
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
Tags
- 연산자오버로딩
- STL
- 포인터
- 제네릭프로그래밍
- 참조자
- 기본클래스
- 점프투파이썬
- 코딩테스트
- 상속
- 주피터
- C++
- 깊은복사
- 인프런
- 스택
- 다형성
- 멤버함수로구현
- 유도클래스
- 람다식
- 코드잇
- 얕은복사
- 동적바인딩
- 데이터사이언스
- 11382번
- c++코딩테스트합격자되기
- 백준
- 프로그래머스lv2
- list comprehension
- python
- OOP
- OpenCV
Archives
- Today
- Total
WjExplor Story
위클리 페이퍼 진행_2026.01.05 본문
NLP 모델과 전처리 기법
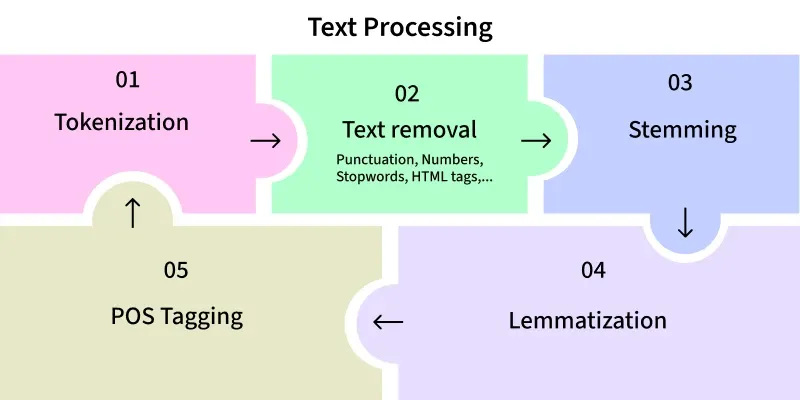
1. 텍스트 데이터 전처리 과정
1.1 토큰화 (Tokenization)
- 단어 토큰화: 문장을 개별 단어로 분리
- 서브워드 토큰화: BPE, WordPiece 등으로 미등록 단어 문제 해결
- 문자 토큰화: 문자 단위로 분리
1.2 정제 (Cleaning)
- HTML 태그, 특수문자 제거
- 대소문자 통일
- 공백 및 중복 문자 처리
- 노이즈 데이터 필터링
1.3 정규화 (Normalization)
- 어간 추출 (Stemming): 단어의 어간 추출 (running → run)
- 표제어 추출 (Lemmatization): 문맥을 고려한 기본형 변환
- 불용어 제거 (Stopwords removal)
- 약어 및 이모티콘 처리
1.4 수치화 (Numeralization)
- 정수 인코딩: 각 단어를 고유 정수로 매핑
- 원-핫 인코딩: 희소 벡터 표현
- 임베딩: Word2Vec, FastText, BERT 등의 밀집 벡터
1.5 패딩 및 시퀀스 처리
- 고정 길이로 맞추기 (Padding/Truncation)
- 배치 처리를 위한 길이 조정
출처 : https://www.geeksforgeeks.org/nlp/text-preprocessing-for-nlp-tasks/

출처 : https://www.geeksforgeeks.org/nlp/nlp-how-tokenizing-text-sentence-words-works/
2. FastText vs Word2Vec
2.1 Word2Vec의 한계
- 단어 단위 학습: 각 단어를 독립적인 단위로 처리
- 미등록 단어 처리 불가: 학습 데이터에 없는 단어는 벡터 생성 불가
- 형태론적 정보 무시: "teaching"과 "teacher"의 관계를 학습하지 못함
2.2 FastText의 핵심 차이점
서브워드 정보 활용
- 단어를 문자 n-gram으로 분해
- 예: "apple" → <ap, app, ppl, ple, le>
- 각 n-gram의 벡터를 합산하여 최종 단어 벡터 생성
수식 비교
Word2Vec: v(단어) = 임베딩 벡터
FastText: v(단어) = Σ v(n-gram_i) / n2.3 FastText의 장점
미등록 단어 처리
- 새로운 단어도 n-gram 조합으로 벡터 생성 가능
- "smartphone"을 학습하지 않아도 "smart", "phone" n-gram으로 유추
형태론적 유사성 학습
- "run", "running", "runner"의 관계 파악
- 접두사, 접미사 정보 활용
희귀 단어 표현 향상
- 적은 빈도로 등장하는 단어도 서브워드 정보로 보완
다국어 처리
- 교착어(한국어, 터키어)나 합성어가 많은 언어에 효과적
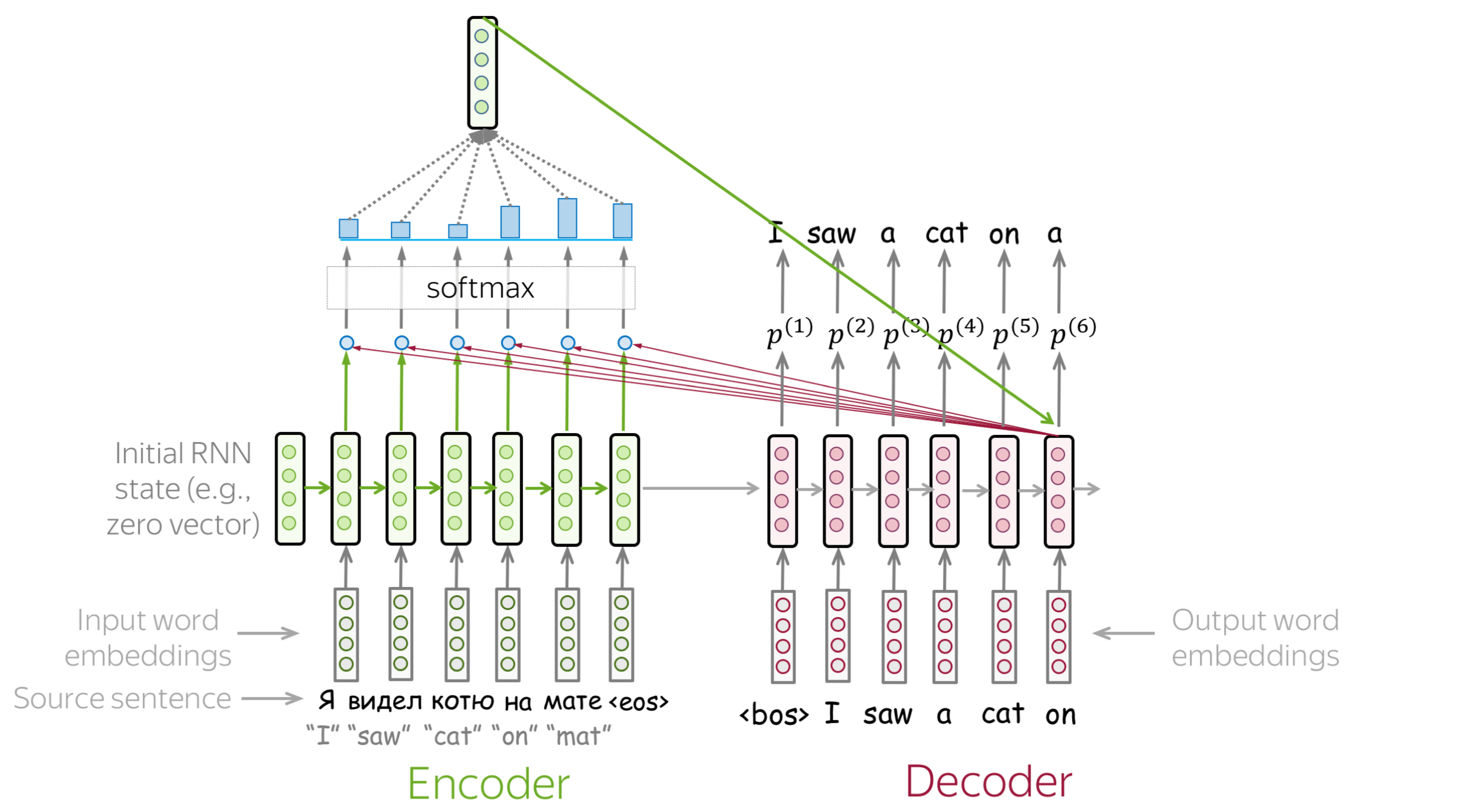
3. Attention 메커니즘과 Seq2Seq 문제 해결
3.1 기존 Seq2Seq의 문제점
정보 병목 현상 (Information Bottleneck)
- 인코더가 전체 입력 시퀀스를 고정 크기 벡터(컨텍스트 벡터)로 압축
- 긴 문장일수록 초반 정보 손실
- 모든 정보를 하나의 벡터에 담아야 하는 한계
장거리 의존성 문제
- 문장이 길어질수록 성능 급격히 저하
- LSTM/GRU로도 완전히 해결 불가
3.2 Attention 메커니즘의 해결책
동적 컨텍스트 벡터 생성
- 디코더의 각 시점마다 인코더의 모든 hidden state 참조
- 현재 출력과 관련 있는 입력 부분에 가중치 부여
작동 원리
1. 각 디코더 시점에서 모든 인코더 hidden state와 유사도 계산
2. 유사도를 확률 분포로 변환 (Attention weights)
3. 가중 평균으로 컨텍스트 벡터 생성
4. 컨텍스트 벡터와 디코더 상태를 결합하여 출력 생성3.3 Attention의 효과
장문 처리 성능 향상
- 문장 길이에 따른 성능 저하 완화
- 필요한 정보를 직접 선택적으로 참조
해석 가능성
- Attention weight 시각화로 모델의 집중 부분 확인
- 번역/요약 시 어느 부분을 참조했는지 파악 가능
정렬 문제 해결
- 입출력 순서가 다른 언어 쌍에서도 효과적
- 예: 한국어-영어 번역 시 어순 차이 처리
출처 : https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html
4. Transformer vs Seq2Seq 구조적 차이
4.1 근본적인 패러다임 전환
Seq2Seq (RNN 기반)
- 순차적 처리: t=1 → t=2 → t=3 ...
- 이전 시점 계산 완료 후 다음 시점 처리
- 병렬화 불가능
Transformer
- 완전한 병렬 처리
- Self-Attention으로 모든 위치 동시 참조
- RNN/CNN 구조 완전 제거
4.2 핵심 구조 차이
1. Self-Attention 메커니즘
Seq2Seq: 인코더 → 디코더 간 Attention만 존재
Transformer:
- Encoder Self-Attention: 입력 내 단어 간 관계
- Decoder Self-Attention: 출력 내 단어 간 관계
- Encoder-Decoder Attention: 입출력 간 관계2. 위치 인코딩 (Positional Encoding)
- RNN은 순서 정보가 자동으로 반영됨
- Transformer는 위치 정보를 명시적으로 추가
- 사인/코사인 함수 또는 학습된 임베딩 사용
3. Multi-Head Attention
- 여러 개의 Attention을 병렬로 수행
- 다양한 관점에서 관계 학습
- 예: 8개 head → 8가지 다른 representation 학습
4.3 구조적 장점
병렬 처리 효율성
- GPU 활용도 극대화
- 학습 속도 대폭 향상 (수십~수백 배)
장거리 의존성
- 직접 연결로 gradient 전달 경로 단축
- 문장 길이와 무관하게 일정한 연산 횟수
확장성
- 레이어 수, head 수 조정으로 모델 크기 조절
- BERT, GPT, T5 등 다양한 변형 가능
4.4 주요 차이 요약
| 구분 | Seq2Seq | Transformer |
|---|---|---|
| 처리 방식 | 순차적 | 병렬적 |
| 핵심 구조 | RNN/LSTM/GRU | Self-Attention |
| 위치 정보 | 암묵적 | 명시적 (Positional Encoding) |
| 계산 복잡도 | O(n) 시간 | O(1) 시간 (but O(n²) 공간) |
| 장거리 의존성 | 어려움 | 우수함 |
| 병렬화 | 불가능 | 가능 |
'AI 엔지니어 부트캠프 > 자연어 처리와 대규모 언어모델' 카테고리의 다른 글
| 위클리페이퍼_2026.02.01 (0) | 2026.02.01 |
|---|---|
| 위클리 페이퍼 진행_2026.01.26 (1) | 2026.01.26 |
| 위클리 페이퍼 진행_2026.01.19 (0) | 2026.01.19 |